
大模型训练推理设备选型
作者:小编
更新时间:2025-08-04
点击数:
以下是大模型训练及推理选型的系统性指南,结合硬件、框架、优化技术和场景需求,分为核心模块进行说明:
⚙️一、硬件选型:GPU关键指标与场景适配
训练场景需求(高算力、大显存、多卡协同):
- 旗舰级GPU:
- NVIDIA H100(Hopper架构):80GB HBM3显存,3.9TB/s带宽,FP16算力1671 TFLOPS,适合千亿参数级训练。
- NVIDIA A100(Ampere架构):80GB版本显存带宽2039GB/s,分布式训练效率高,性价比之选。
- 中等规模训练:
- A6000(48GB GDDR6):适合中小模型训练,显存充足但带宽(768GB/s)低于数据中心级GPU。
- 成本敏感场景:
- 多卡V100(32GB HBM2)
 :二手市场成本低,适合百亿参数模型。
:二手市场成本低,适合百亿参数模型。
推理场景需求(低延迟、能效比、单卡能力):
- 高性能推理:
- L40s(48GB GDDR6):FP16算力731 TFLOPS,支持高并发结构化查询。
- A6000:平衡显存与算力,适用批量推理任务。
- 轻量级/边缘推理:
- L4(24GB GDDR6):能效比优异,适合视频/图像处理。
- RTX 4090(消费级):24GB显存,中小模型推理性价比方案。
⚙️二、框架选型:训练与推理工具链
训练框架(分布式支持、显存优化):
| 框架 | 核心优势 | 适用场景 |
|---|---|---|
| PyTorch + DeepSpeed | ZeRO-3显存优化、混合精度训练,8卡A100训练65B模型 | 大规模分布式训练、学术研究 |
| Megatron-LM | 万亿参数级模型支持,序列并行技术 | 超大规模模型生产训练 |
| Hugging Face Transformers | 预训练模型库丰富(BERT/GPT等),集成Accelerate多硬件支持 | 快速微调、NLP任务迁移学习 |
推理框架(吞吐量、延迟优化):
| 框架 | 核心技术 | 优势场景 |
|---|---|---|
| vLLM | PagedAttention、动态批处理 | 企业级高并发(24倍于Hugging Face) |
| TensorRT-LLM | TensorRT深度优化、FP8量化 | NVIDIA GPU极致延迟优化(在线服务) |
| Ollama | 本地化一键部署、1700+模型支持 | 个人开发/隐私敏感场景(离线运行) |
| Hugging Face TGI | 连续批处理、REST API支持 | 云端生产环境稳定部署 |
⚙️三、性能优化关键技术
精度压缩:
- 权重8-bit/4-bit量化(如GGML格式),显存占用降至1/3,但需平衡精度损失。
- 工具:AWQ(激活感知量化)、SmoothQuant(训练后量化)。
- 混合精度训练(FP16/BF16):提速20%,显存减半。
- 量化推理:
批处理与并行:
- 连续批处理(vLLM):动态插入新请求,GPU利用率提升30%+。
- 张量并行(Tensor Parallelism):多卡分摊大模型负载(如Falcon-40B需2*A6000)。
模型轻量化:
- 适配器微调(LoRA/QLoRA):仅训练0.1%参数,显存节省70%。
- 结构化剪枝(LLM-Pruner):删除冗余权重,模型体积压缩50%。
⚙️四、场景化选型建议
| 需求场景 | 推荐方案 |
|---|---|
| 千亿参数训练 | H100集群 + Megatron-LM + ZeRO-3优化 |
| 中小模型微调 | A100/A6000 + PyTorch + LoRA量化 |
| 高并发在线推理 | vLLM/TensorRT-LLM + A100/L40s,启用连续批处理 |
| 边缘设备部署 | Ollama/Llama.cpp + L4/RTX 4090,4-bit量化 |
| 国产硬件环境 | LMDeploy(昇腾GPU优化)+ 华为Atlas系列 |
⚙️五、决策流程图
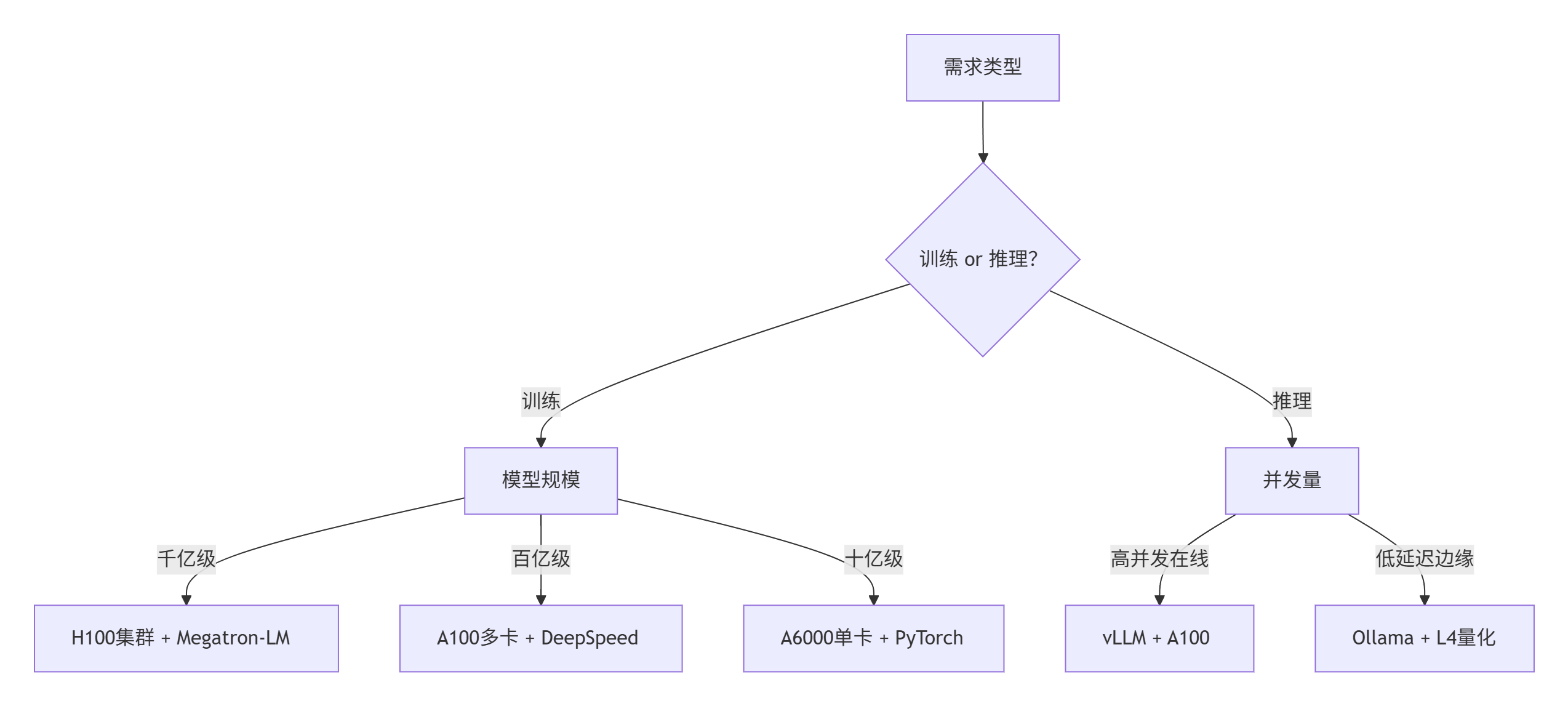
注:价格参考(以云服务为例):H100实例约3.09/小时,需结合成本优化资源配置。
通过硬件-框架-优化技术的协同选型,可平衡效率、成本与场景需求。实际部署前建议小规模测试框架兼容性及量化精度损失。




